本文轉自驅動之家
過去每一年開頭的CES大展上,NVIDIA都會帶來新一代的Tegra移動處理器。盡管過去兩代表現一般,但是黃仁勛還是親自登臺,推出了全新的Tegra X1。

【GPU:強大的麥克斯韋】
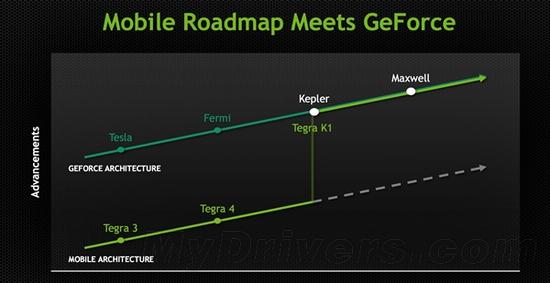
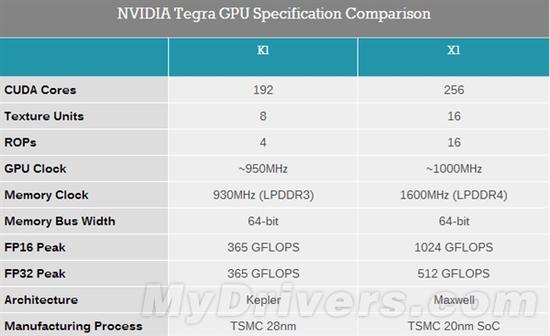
首先,NVIDIA是一家GPU公司,因此無論在桌面還是移動市場上,都對GPU異常重視。去年的Tegra K1首次引入了與桌面平級的開普勒架構,192個流處理器帶來了驚人性能。今年的Tegra X1則進一步升級為麥克斯韋架構,流處理器也增至256個。
換句話說,去年用的是一組陣列(SMX),今年則是兩組(SMM)!隨之而來的是,紋理單元、ROP單元也都大大增強了,均有16個,尤其后者翻了兩番,對于驅動4K 60Hz顯示有很大好處。
從初步測試結果看,Tegra X1 GPU性能依然彪悍,可以輕松搞定蘋果A8X里八核的PowerVR GXA6850。

在時間上,開普勒誕生了將近兩年才走入移動平臺,麥克斯韋架構只用了一年。更確切地說,Tegra X1用的是第二代麥克斯韋架構,而它在桌面上才出現了一個季度多點而已。
這也說明,NVIDIA的新架構從一開始就為移動平臺進行了同步優化,所以我們才屢次看到麥克斯韋的能效是那么高,功耗是那么低。
新架構的諸多圖形技術也被帶了過來,包括更高效的CUDA核心、更簡練的SMM陣列、第三代Delta色彩壓縮、保守光柵化算法、體積區塊資源(DX11.2)、多幀抗鋸齒(MFAA)等等。
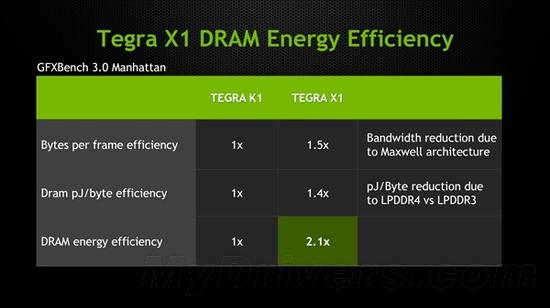
更重要的是內存帶寬,這一直是限制移動SoC的瓶頸,傳統方法就是增加位寬,但會大大提高復雜度和成本。
Tegra X1還是停留在64-bit位寬,但是大大增強了內存壓縮,包括剛才說的第三代Delta色彩壓縮,以及新的端到端壓縮。再輔以新的LPDDR4(頻率可達1600MHz),內存帶寬基本不是問題。
然后值得一提的就是半精度FP16的支持,NVIDIA稱之為“雙倍速FP16”(Double Speed FP16)。
和開普勒一樣,麥克斯韋架構也只有專門的單精度FP32、雙精度FP64 CUDA核心,并沒有給FP16分配獨立資源,只是在操作方式上做了改變。
Tegra K1 FP16操作會被給予和FP32相同的待遇,每一個都交給FP32 CUDA核心處理。Tegra X1上如果條件允許,則會將兩個FP16合并成一個Vec2,交給單獨一個FP32 CUDA核心去處理。
這里的前提是兩個FP16操作屬于同一類型,比如都是加法或者乘法,甚至是乘加運算(FMA)。
所以說,NVIDIA宣稱的原生支持FP16并不完全準確,只不過耍了個花招而已,比對手還是差一些。ARM Mali、Imagination PowerVR都有獨立的FP16單元,AMD GCN 1.2版也會引入。
FP16在安卓的顯示合成里使用非常多,游戲里也能看到,但更重要的是,它還能參與圖形計算,比如圖像識別什么的,比如Drive PX車載平臺里就需要它。

具體頻率還是沒有公布,而按照NVIDIA說的1TFlops FP16浮點性能,那么應該是1GHz(1GHz×2FP16×2FMA×256=1TFlops),比去年略微高了一些。
FP32單精度浮點性能為512GFlops,比去年提高了40%。
 【CPU:為啥不用自主架構?】
【CPU:為啥不用自主架構?】
Tegra K1去年先是使用公版的四核A15,然后終于用上了NVIDIA自己苦心研發多年的64位自主架構“丹佛”,按理說今年只能是丹佛的增強版,甚至上四核,但結果卻是四核A57加四核A53這種大路貨。
究竟發生了什么?可以從路線圖的變更上揣測一番。
Tegra K1的開發代號是“Logan”,金剛狼洛根,它之后本來應該說是“Parker”,另一位超級英雄蜘蛛俠帕克,說是會有丹佛架構CPU、麥克斯韋架構GPU、(16nm)FinFET制造工藝。
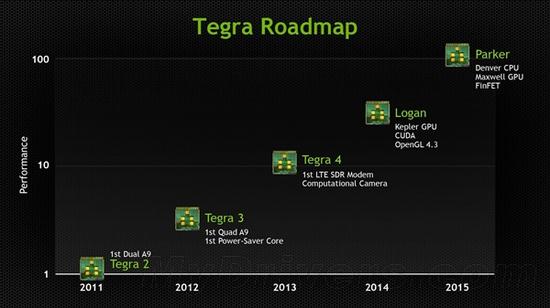
但去年3月底的時候,NVIDIA將其改成了“Erista”,金剛狼的兒子,而且只標注了麥克斯韋GPU架構,CPU和工藝根本不提。
如此一來就很好說了:計劃不如變化,臺積電的16nm FinFET工藝雖然速度很快,但還是無法滿足NVIDIA的進度要求,只能退而求其次,先用20nm的頂一陣子,相當于臨時加了一步棋(要說這代號也取 得很妙),這樣時間上自然很緊迫,照搬公版架構就在情理之中了。
按照目前的跡象,Tegra X1應該會只有這一個版本,更美好的事情得等明年。

具體來說,Tegra X1 A57核心搭配了2MB共享二級緩存,每個核心還有48KB一級指令緩存、32KB一級數據緩存,A53核心則共享512KB二級緩存,同時每個核心有32KB一級指令緩存、32KB一級數據緩存。
不過,NVIDIA并沒有使用ARM big.LITTLE雙架構體系、CCI-400互連總線,而是自己設計了互連總線,還讓全部八個核心可以同時運行,系統和應用可以隨意調用。
而且,該系統是緩存一致性的,所以不會像類似方案那樣損失功耗和性能。
NVIDIA宣稱,Tegra X1的能耗比與三星Exynos 7410是齊平的,同等功耗下性能高出40%,同等性能下功耗少50%。——兩家都是20nm。

內存支持從LPDDR3升級為LPDDR4,位寬仍然是64-bit,峰值帶寬從14.9GB/s增至25.6GB/s,能效也提升了大約40%。
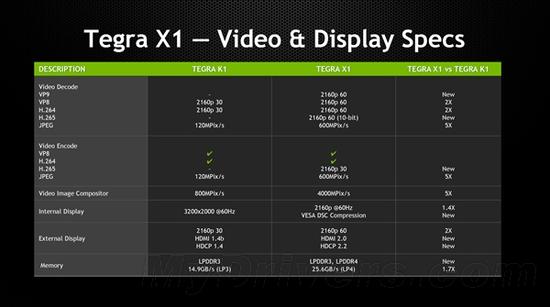
最大內部分辨率也從3200×2000@60Hz增強到了3840×2160@60Hz,并支持VESA顯示流壓縮。
外部顯示方面支持HDMI 2.0、HDCP 2.2,意味著可以搞定4K@60Hz,而上代只有4K@30Hz。
ISP JPEG編碼解碼速度加快了4倍,同時新增4K@60Hz H.265(10-bit)、VP9解碼,但是編碼僅支持4K@30Hz H.265。
H.264、VP8解碼也都提升到了4K@60Hz。
哦對了,存儲支持eMMC 5.1。
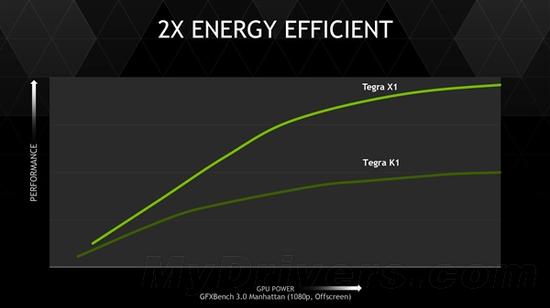
最后的最后,功耗。這是一個很敏感的問題,NVIDIA乃至幾乎所有廠商歷代都在刻意回避,從不公布具體的功耗指標。這一次NVIDIA也只是說能效比上代提高了一倍。
據說Tegra X1現場展示的需要大約10W,其中GPU非常低,電老虎還是CPU部分。