
賽靈思日前正式在全球發布其“堆疊硅片" title="堆疊硅片">堆疊硅片互聯技術”,旨在超越摩爾定律" title="摩爾定律">摩爾定律的束縛。在賽靈思啟動目標設計平臺戰略時,他們提到要進行統一架構的產品路線。而該公司不久前推出的7系列FPGA" title="FPGA">FPGA中,有關邏輯架構、Block RAM、時鐘技術、DSP切片和Select I/O已經完全相同。現在,與7系列一樣,堆疊硅片互聯的實現同樣基于ASMBL模塊架構,統一架構產品路線的終極目標正式曝光。
升級面臨瓶頸
目前FPGA工藝已經到達28nm節點,但市場對于更多的邏輯容量、高速串行收發器、內存等的需求依舊孜孜不倦,摩爾定律的瓶頸日益突出。賽靈思亞太區執行總裁湯立人認為,如果沿著摩爾定律開發更大規模的FPGA,一是良率會越來越低,二是平均要花2年左右時間才能實現量產,這顯然不符合市場需求的節奏。此外,如果要通過PCB或MCM上集成多個FPGA芯片來實現大型FPGA的功能,則目前最大型的FPGA只有1200個pin可用,I/O資源有限,時延過長并且功耗會增加,這些都限制了門電路的性能。“堆疊硅片互聯技術為FPGA帶來全新密度、帶寬和節能優勢,”湯立人說,“相對于單片器件,單位功耗的芯片間帶寬提升了100倍,容量提升2倍~3倍。”
技術如何實現
賽靈思亞太區市場及應用總監張宇清表示,堆疊硅片互聯技術在單個封裝中集成了4個28nm工藝的FPGA切片(圖1),以實現突破性的容量、帶寬和功耗優勢,其高密度晶體管和邏輯能夠滿足對處理能力和帶寬性能要求極高的需求。該技術通過采用3D封裝技術和硅通孔 (TSV) 技術來突破摩爾定律的限制,利用堆疊硅片互聯封裝方法可以在現有工藝節點提供200萬個邏輯單元。

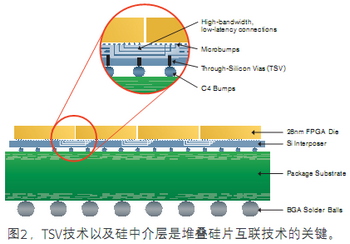
湯立人詳細介紹了有關細節:在堆疊硅片互聯結構中,數據在一系列相鄰的FPGA芯片上通過1萬多個過孔走線。相對于必須使用標準I/O連接在電路板上集成兩個FPGA而言,堆疊硅片互聯技術將單位功耗芯片間連接帶寬提升了100倍,時延減至五分之一,而且不會占用任何高速串行或并行I/O資源。在堆疊硅片互聯技術中,無源硅中介層由TSMC提供,它有四層導線層,是堆疊互聯的關鍵(圖2)。由于中介層無源,因此不存在散熱問題,它使得建立在該技術上的超大規模FPGA相當于單芯片。
“由于較薄的硅中介層可有效減弱內部堆積的應力,一般說來堆疊硅片互聯技術封裝架構的內部應力低于同等尺寸的單個倒裝BGA封裝,這就降低了封裝的最大塑性應變,熱機械性能也隨之得以提升。”湯立人表示,“通過芯片彼此相鄰,并連接至球形柵格陣列,可以避免采用單純的垂直硅片堆疊方法出現的熱通量和設計工具流問題。”
為了實現堆疊硅片互聯,賽靈思花了五年時間進行研發,并與TSMC和Amkor(封裝廠)在制造流程上進行了深度合作。為了表示對這一先進技術的重視,TSMC研究及發展資深副總經理蔣尚義博士親臨賽靈思臺北發布現場。他指出,多芯片封裝FPGA提供了一個創新的方法,不僅實現了大規模的可編程性、高度的可靠性,還提高了熱梯度和應力容限特性。通過采用TSV技術以及硅中介層實現硅芯片堆疊方法,基于良好的設計測試流程,可大大降低風險實現量產。
工具高效支持
針對堆疊硅片互聯技術,賽靈思將在其ISE 13.1設計套件中提供新的功能,其中有設計規則檢查(DRCs)和軟件信息可引導用戶實現FPGA芯片間的邏輯布局布線。此外,PlanAhead和FPGA Editor功能增強了基于堆疊硅片互聯技術的FPGA器件的圖示效果,有助于開展互動設計布局規劃、分析及調試。此外,該軟件可自動將設計分配到FPGA芯片中,無需進行設計分區,并遵循芯片間和芯片內的連接和時序規則。如果需要,用戶亦可在特定FPGA芯片中進行邏輯布局規劃。
據悉,目前代號TV3的測試芯片已經通過設計驗證和工藝鑒定,首先采用堆疊硅片互聯技術的將是28nm Virtex-7 2000T,其邏輯容量是目前賽靈思帶串行收發器的最大型40nm FPGA的3.5倍以上,同時也是最大競爭型的帶串行收發器 28nm FPGA 的2.8倍以上,預計首批產品將于2011年下半年開始供貨,其目標市場將是下一代通信、醫療、測試和測量、航空航天和國防、高性能計算以及ASIC 原型 設計仿真。